Hinode Science Data Centre Europe - Science Archive
30 May 2007
A new kind of science archive with previously unheard-of search capabilities and services became available to the solar physics community on 27 May, when the proprietary data period for Hinode data ended.The Hinode Science Data Centre (SDC) Europe has been developed at the Institute of Theoretical Astrophysics, University of Oslo, through the Norwegian Space Centre, as part of ESA's and Norway's contribution to the Hinode mission. The other part of the contribution is to increase the amount of downlinked data by about a factor of four, using ground stations located at Svalbard.
 |
|
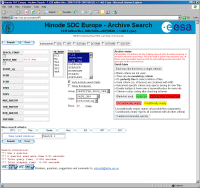
The Hinode science archive search page at the SDC in Oslo, Norway |
"We started off from a very different direction than most archive developers do," says Stein Vidar Hagfors Haugan, Executive Director at the data centre and former ESA Science Operations Coordinator for SOHO.
Most mission or multi-mission archives are based on the notion of common keywords or attributes for all observations. This tends to limit the search results to too narrow a window on the full extent of the actual available data in the archive.
What if you really want to ask the big question for a joint observation: "I want several instruments on Hinode, each having observed within a range of instrument-specific parameters, simultaneously with an instrument on-board SOHO having observed within its own range of specific parameters, all pointed at the same object, and the observations should contain a specific event or feature, with the observations being made at any point in time available in the archive."
Multi-mission archives typically can't even begin to answer the first part, because the instrument-specific information isn't available for searching even if it is inside the data files themselves. And many archive interfaces also insist on limiting the search to a specific time period, or the search would just take too long.
While the archive in Oslo is not yet able to answer the big question in full, it is getting close after one year of intensive development by a three-man group with good support from the institute's infrastructure and system administrators.
Design and Testing
The primary design criterion was speed. Without it, few people would bother using the archive, and development goes slower as well. Second on the list was inclusiveness: the ability to include every available piece of information for each file. Since the instrument-specific keyword definitions were mostly unknown at the time the development started, a third requirement was to have a flexible system that would easily assimilate the final keyword definitions chosen by the instrument teams. This flexibility is maintained in the final archive. In principle, it takes only a few minutes to add another attribute, available for searching through the archive's web interface. It does take longer to fully populate the archive with the corresponding values, however, depending on what kind of reprocessing is needed to find the values.
To test the archive for speed, it needed to be populated with the expected amount of data. Also, the processing pipeline needed to be tested, to make sure it would be able to handle every aspect of day-to-day operations, recovery from a backlog situation, or disaster recovery.
The data volumes in the Hinode archive are significant: 2 million compressed fits files with 1.5 terabytes of data after just half a year, and about 20 million images and thumbnails to go with them. For the testing of the archive, 6 million dummy files were made based on educated guesses and moved around from one machine to another, exercising the database designs and processing pipeline from end to end. In addition, separate tests were made for volume transfers from Japan, since there was no dummy data available there.
"This particular aspect gave us great confidence during the Readiness Review last fall," says Fleck. "Although it had not been possible to do a real end-to-end test with dummy telemetry going through the systems in Japan, it was clear that the systems from there on, all the way to the end user, would be up to the task".
In November last year, just two weeks after the first data files became available, the archive was ready to serve users and in principle development could have stopped there. "It was perfectly adequate, and could answer the first two parts of the big question in isolation, and display the result together: show me observations from two different instruments on Hinode, each with their own instrument-specific parameters," says Haugan. However, as the Hinode data could not be made public until 27 May, the extra months were used by the development team to further improve the archive's usability.
Latest Developments and the Future
A lot of time has been spent on adding extra features, such as images and thumbnails for all files, an IDL-based client for the archive, and new ways of browsing, summarising & selecting data. The two latest developments were just ready for the opening:
- an interactive search page with feedback, and
- a system for in-house mass-processing of data with IDL programs submitted by archive users
The interactive search page uses AJAX (Asynchronous Javascript And XML) technology to accomplish two things:
- the search results are just about ready even before the search button is hit (usually only sorting remains)
- and the user is warned almost instantly if criteria or combinations of criteria are entered that result in empty or failed searches
The mass-processing system was developed to help answer the last part of the big question: which files contain data showing specific characteristics, features, or events. With the system that has been developed, user-defined processing of very large volumes of data can be done without the need for downloading any data at all.
For this system the image-making process was used as a prototype: it produces results for searching (the number of preview images produced for each file) and a bulk data product (the images themselves). The idea behind the system is to cut down on the time spent downloading and processing data sets that don't contribute to your research. Introducing new processing methods submitted by users is still experimental, but interested parties should contact the data centre at  astro.uio.no
astro.uio.no
The development of the archive will not end there. It is the intention to build the first archive that's able to answer in a comprehensive way the full question: "Has a similar joint observation been done successfully before?"
Contact
Stein Vidar Hagfors Haugan
Executive Director, Hinode Science Data Centre Europe
E-mail: s.v.h.hauganastro.uio.no
Bernhard Fleck
ESA SOHO and Hinode Project Scientist
E-mail: bfleckesa.nascom.nasa.gov